


It was a lovely morning, sunlight was pouring through a window down to my desk. With a mug full of hot coffee in my hand, I was slowly walking into the room towards my office, confident and excited. Today is THE day, I whispered, today I will beat my latest Digit Recognizer submission at Kaggle! By the time I reached my chair, I was full of energy! Clicked the mouse to wake up my PC, and in a matter of milliseconds, entered my password. I paused for a moment… “I have never written my password so fast in the past,” I thought, and quickly opened 15 tabs in Google Chrome at once! News, fun blog posts, Twitter, YouTube, and many more appeared on my screen, but there was something that would change the course of history, well… not history but definitely my day.
It was a video that caught my eye, a video from Julien Simon, talking about AutoML, SageMaker AutoPilot.
“Well…“, I said, “I guess it does not hurt to watch a video while I am drinking my coffee. I will beat my past self in Kaggle in a minute, it can wait…”
Details about the post:
- Level difficulty: 200
- Money spent: ~20$ (stopped the trial at 3 hours) It can get expensive!
Amazon SageMaker Studio
Amazon SageMaker Studio is a new, refactored look of SageMaker that was announced at re:Invent 2019. It is an IDE for Machine Learning, full of new features and services. SageMaker studio is perfect for Data Science teams. Leaving behind the instance type notebooks, Studio now has Jupyter Lab with multiple users and a friendly interface. You can now spawn Jupyter notebooks in seconds (Serverless 

So I clicked the play button… “What is SageMaker Experiments and AutoPilot?” I wondered… While I was watching Julien go though the experiments tab, my jaw dropped. “Two clicks and you have a fully trained model with no pre-processing, no feature engineering, no parameter tunning?? This is Heaven!” Well, to be honest, it is not my Heaven, but I am sure it is someone’s Heaven. I like doing the manual processes that eventually lead you to model selection, training, parameter tuning, etc. But that thing! Oh, my God! I had to try it, it was too good to be true! So I quickly logged in to my AWS account and rushed through Ohio (the region). I clicked the Amazon SageMaker Studio button, and promptly I created a user.
Starting with SageMaker Studio
To begin exploring Amazon SageMaker Studio, all you have to do is the following:
- Login to your account and go to SageMaker service
- Switch your Region to Ohio – us-east-2
- Click Amazon SageMaker Studio button on the top of the left sidebar


- Add a username or keep the default one
- Select an existing SageMaker Execution Role or Create a New one
- Press Submit


Once it is ready click the Open Studio button to launch SageMaker Studio


Getting to know Experiments
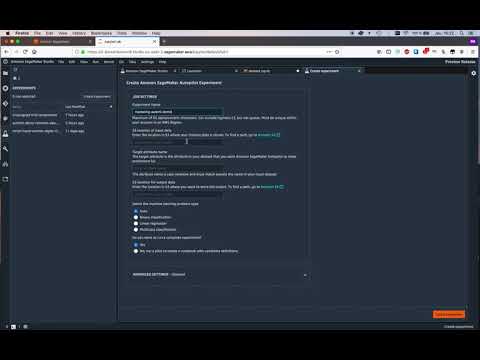
“Ok, that was easy…,” I thought, as I was searching for the Experiment Icon (a small black vial). When I found it (it wasn’t that hard), I clicked Create Experiment, uploaded my dataset to an S3 bucket, as Julien proposed, and defined the target label. I already knew that the problem was a multiclass classification, so I selected that and Clicked Create Experiment!


- Define an experiment name
- Show the location to where your dataset is, mine was something like s3://my-bucket/mnist/train.csv
- Select the column name for your target
- Select an S3 bucket to output the results, in my case I selected: s3://my-bucket/mnist/output
- I picked the Multiclass classification
- I wanted to see the full potential of the experiment
- Create the experiment
“Oh, my God!! This is taking so long!!” I was so excited to see the results but it didn’t cross my mind that this is a very time-consuming process. Four steps have to be completed to get my results:


As you can see, you can stop the experiment at any time, something that I immediately did when I realized this would take hours, and I wasn’t sure of how much money I will have to pay for this. At the bottom line, the whole process took about 4 hours, and I got charged for about 20$, so it was fine.
Reviewing the results
Ok, it took a long time, it makes sense, but it was a loooooong time! When the experiment was complete, I selected the best model and deployed the endpoint. I wanted to say more about this, but it was straightforward… soooo in the bottom line I saw a big star to one of the models, and then I clicked the deploy button. That was it!


This is the code I used to make the predictions.
Aaaaand… Drum roll…

Oh well… Another day, another model… For something that just got a raw dataset and created an XGboost model to predict hand-written digits, it is pretty spectacular! Also, I have a confession to make… I deployed a model before the full trial ended, but the result would have been pretty much the same. I wonder what the result would be if the dataset had raw images or 32x32x3 arrays as input since now we fed the algorithm with a row of features instead of an image. Well, this is something that we will explore in a future post, and in my opinion, the 32x32x3 array breaks the whole point of having pure magic to solve your problems while you drink your coffee in front of your computer and writing blog posts…
That’s it for today folks! I hope you liked it! Any questions or suggestions about the post, you can ask me at the comments section below or find me and ping me at Twitter @siaterliskonsta



